Measurement that changes what happens next.
future.
economy.
company.
Most measurement has an actionability gap. Fospha closed it. Meet the Measurement OS integrated at the heart of the stack — every ad, every marketplace, delivering thousands of incremental outcomes for leading retail commerce brands, every day.















Brands on Fospha's Measurement OS achieve 30% higher ROAS than the market
Fospha gives brands the insight to optimize what’s working today - and the confidence to invest in what drives incremental growth tomorrow. Delivering smarter decisions and stronger returns.







.webp)













.jpg)
.png)
The Fospha advantage
Measure everything
Measure the full impact of every ad on web, Amazon, TikTok Shop and beyond, every day.

Trust the numbers
See the model work. Validate the outcomes.

Act on it everywhere
End-to-end. From insight to action to incremental impact. Automatically.

Know where to grow next
Benchmarks, forecasting, and market intelligence so brands have the proof to do something completely new.

Measurement rebuilt for the rate decisions get made.
Calibrated to move beyond correlation.
Corrected for the bias built into click-based measurement.
Traditional Marketing Mix Models
Fospha's Media Mix Model
Pure correlation
Beyond correlation
Quarterly reports
Daily outputs
Channel-level view
Ad-level granularity
Historical and static
Predictive forecasting
Manual interpretation
Automation-ready
Black-box models
Transparent science
One Measurement OS to report, plan, and optimize across every ad, everywhere you sell, every day.
Measure the full impact of every ad — web, Amazon, TikTok Shop and beyond, daily.
Have the proof to do something completely new, from insight to incremental impact. Automatically.
Core
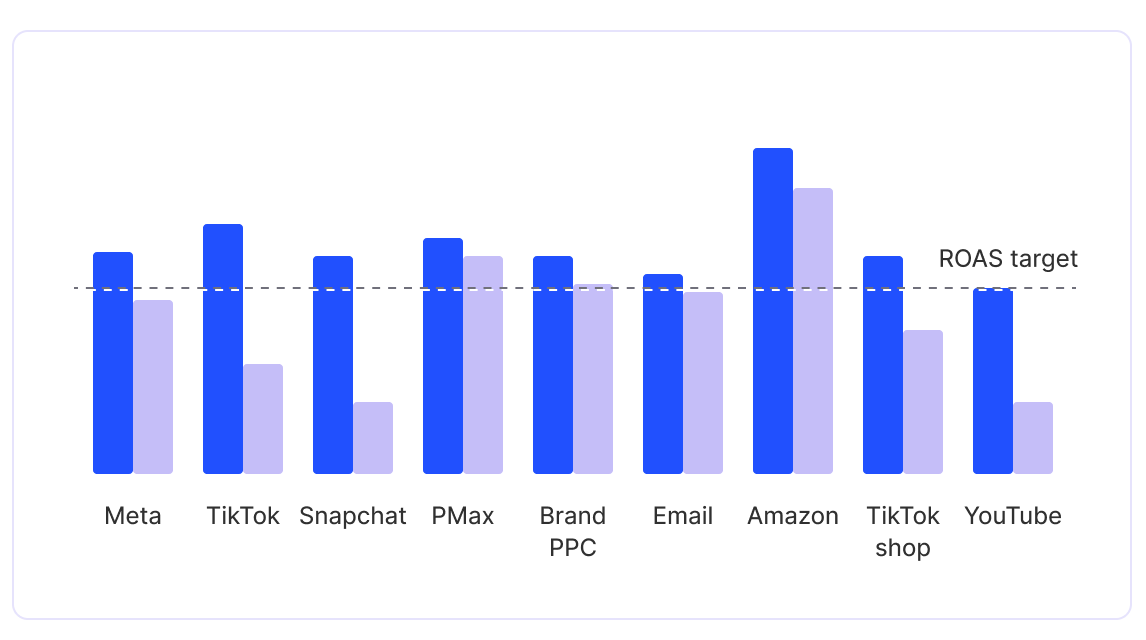
Daily, ad-level measurement that flows directly into the systems that act on it
Spend smarter, grow faster. Fospha's always-on Daily MMM provides tools for all teams - from CMO to channel manager.
Measure and quantify the impact of every impression, view, and click from campaign down to ad-level, across all your sales channels like DTC, Amazon, and TikTok Shop. Fospha delivers strategic insights daily to help brands optimize for short and long-term efficiency.
Beam
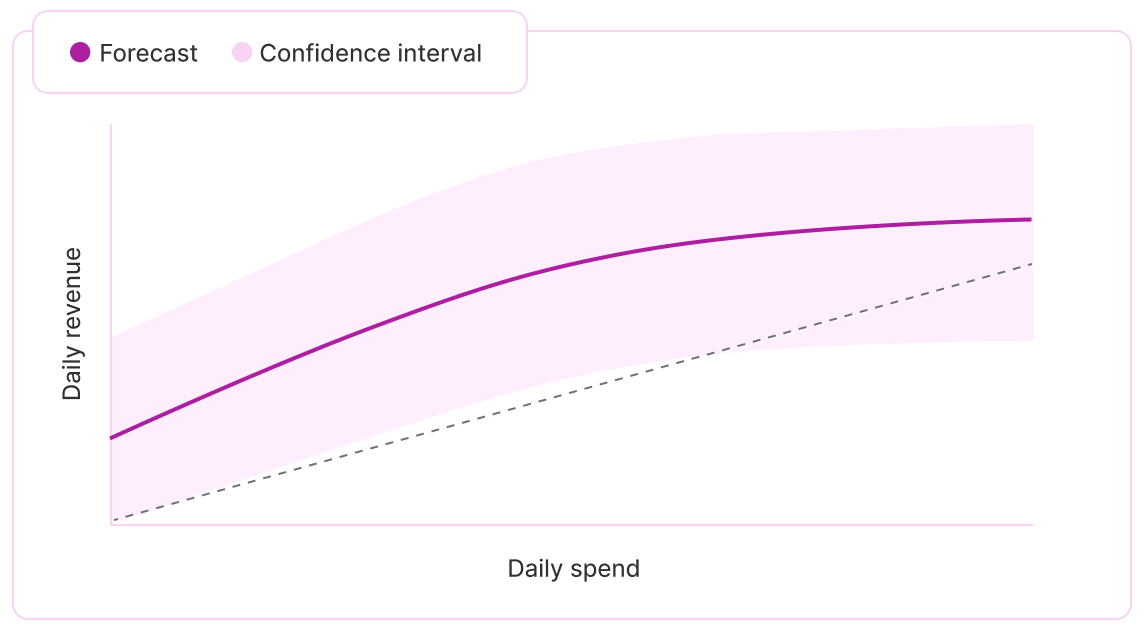
Know your next best dollar — forecast incremental returns
Identify and harness opportunities for profitable growth with Bayesian saturation curves for every channel and objective so you can see exactly how far your budget can go before you spend it.
Forecast ROAS and CAC at different investment levels, pinpoint the point of diminishing returns, and maximize the impact of your marketing budget.
Halo
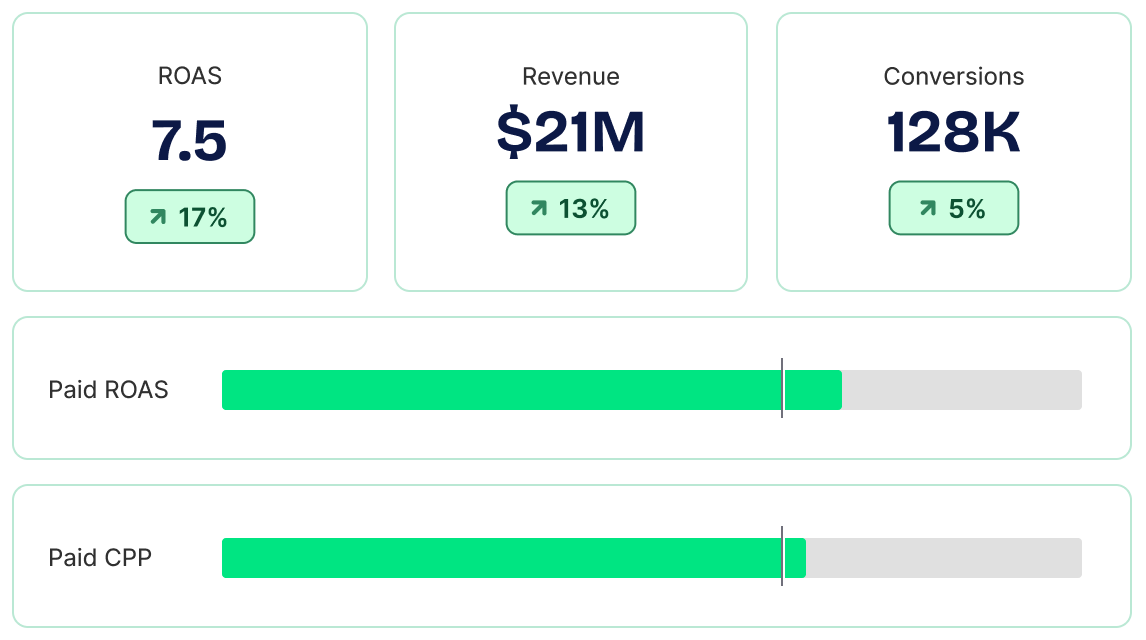
One system — DTC, Amazon, and TikTok Shop
Measuring the cross-channel halo effect on marketplaces is impossible using DTC metrics and tools. Without unified measurement, media budgets miss crucial marketplace revenue.
Halo leverages incremental forecasting models to measure how your paid media drives sales across Amazon, TikTok Shop, and retail marketplaces. Optimize marketplace performance and drive profitable growth.
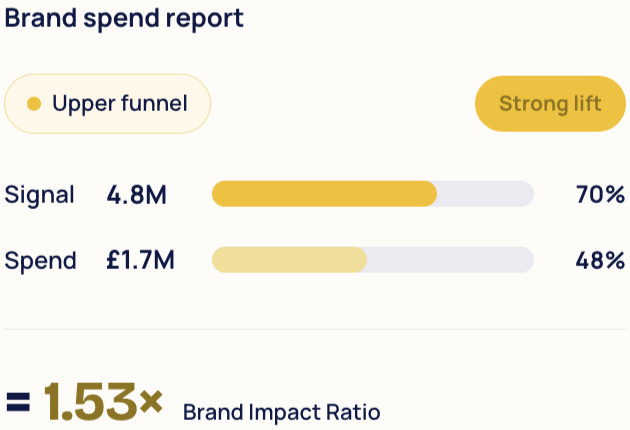
Brand Impact

Prove that brand drives revenue
Prism
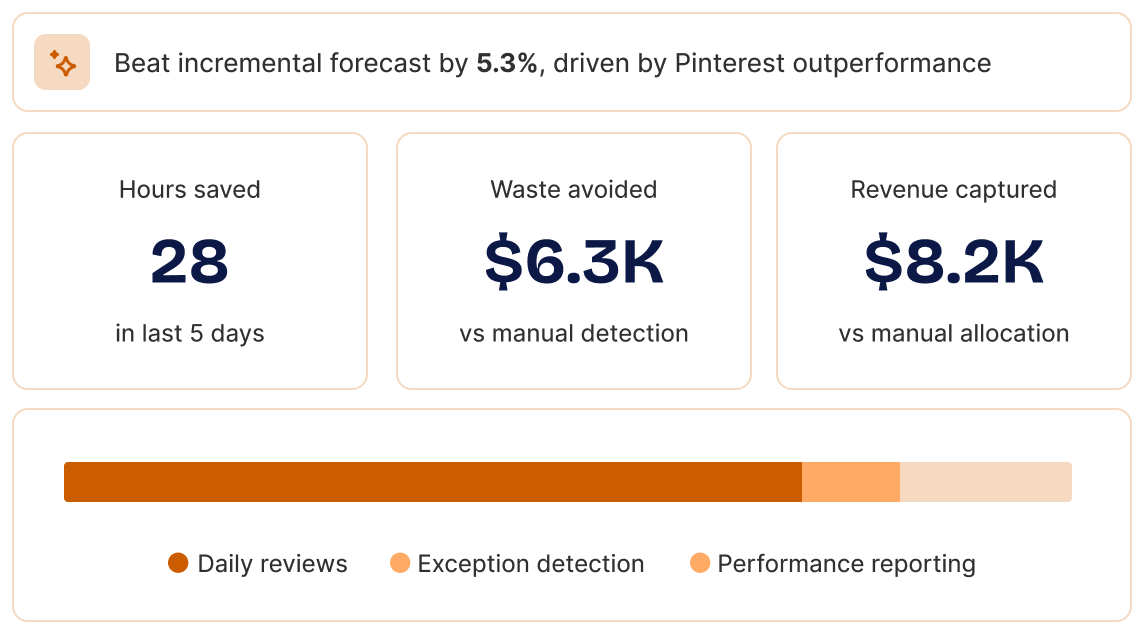
Turn measurement into automated action
Prism delivers incremental growth at scale, especially in channels and markets that get deprioritized when teams are stretched.
Budget changes reflect the full cross-channel impact of your marketing, not just ad platform reporting, so spend never shifts based on silo’d signals.
Channel efficiency improves automatically — Prism reduces budgets when performance drops, so no dollar stays in an underperforming campaign longer than it should.
Fospha AI
Ask Fospha AI
Ask your Fospha data anything. Get answers to your performance questions directly in the Fospha dashboard, or connect your data to the AI tools you already use with our MCP.
Inside Fospha, it's your in-dashboard marketing strategist. Ask any performance question and get the answer the moment you need it.
Outside Fospha, plug your measurement into the AI tools your team already uses — like Claude or ChatGPT. Build a workflow once and have a report land in your exec team's inbox every week.
The science that makes trust possible and action inevitable.
Over a decade of R&D, built by the same team using the same methodology that has powered growth for Gymshark, Huel, Dyson, and hundreds of the world's fastest-growing retail brands. The result is a proprietary, always-on measurement system with a Media Mix Model at the core, delivering what legacy tools can't: daily, impression-led, full-funnel measurement that is transparent, validated, and ready to power automation.

End-to-end. Every team. Every decision. Driving incremental outcomes, every day.
Our Measurement OS unites Finance, Marketing, Data, and Leadership with a shared view of performance and profitability — combining daily measurement, forecasting, and optimization.
Maximize the impact of your marketing budget
See the true impact of all your marketing activity across every sales channel, pinpoint where you have room to grow profitably, and make the most of every dollar in your marketing budget


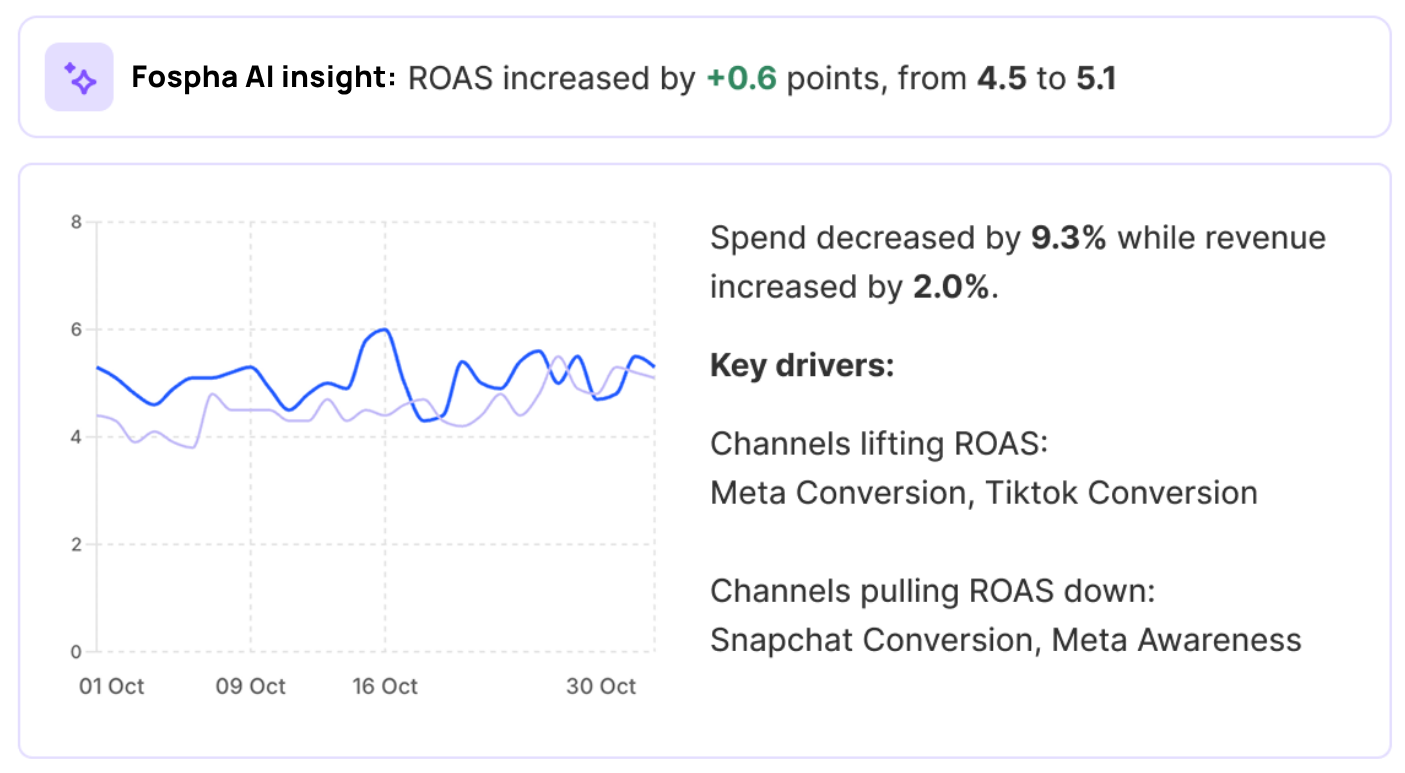
Understand your true marketing ROI for smarter spending
With Fospha, see the true ROI of all your channels, make smarter budget decisions, and escape the bottom-of-funnel trap.
With automatic, customized reporting directly in your inbox, monitoring the metrics that matter has never been easier.


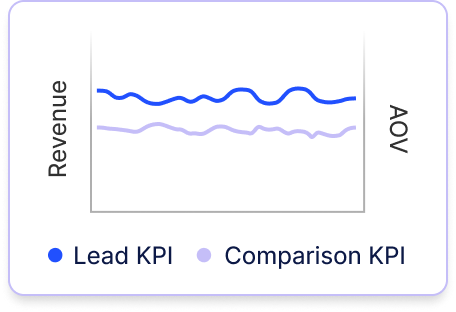
Prove True Channel Impact, Optimize Every Dollar
Instantly spot trends in your data, course-correct quickly, and identify both oversaturated campaigns and top performers with headroom to scale.
Maximize performance and make the most of every dollar in your channel budget.

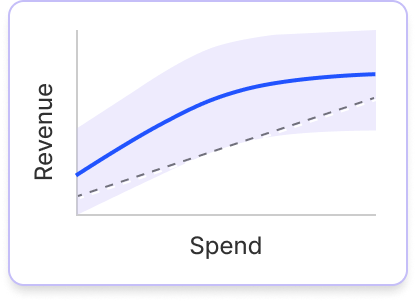
Prove the business impact of brand. Secure future growth
Fospha’s Glow leverages causal reasoning modeling to measure the impact of brand campaigns on the sensitive leading indicators of future performance.
Quantify the impact of brand-building on tangible business outcomes, justify budgets and fuel long-term growth


.avif)
How we embed the Measurement OS
at the heart of your business.
Where evolved measurement enables strategic planning, team alignment, and execution.
1. Data validation
2. Total measurement visibility & growth planning
You gain access to our enterprise-grade model we've pressure-tested across hundreds of retailers. Always-on media mix modeling. Daily training. Ad-level granularity.
This provides both upper and lower funnel visibility, revealing the true impact of your marketing strategy and enables us to develop a mutual success plan that balances short-term wins with long-term sustainable growth.
3. Change management & adoption
We help unite marketing and finance teams around a shared source of truth, facilitating the transition to a new view of measurement. Through regular training sessions, reporting workflows, and optimization insights, we ensure everyone understands the value of daily measurement and can confidently act on the data.
4. Continuous learning
& growth
By connecting Fospha to your tools and workflows, teams across your organisation—from CMO to channel managers—can make smarter, more confident budget decisions that fuel profitable growth.
Hundreds of leading retail brands trust Fospha's Measurement OS



.webp)












Stay ahead with the inside scoop from Fospha.
For over 10 years, we've been leading the change in marketing measurement.




.png)


.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.webp)


.webp)
.webp)
.png)
.webp)

.png)


FAQs
Yes. Fospha MCP connects your Fospha measurement directly to AI tools like Claude and ChatGPT - so you can ask questions about your performance data in plain language and get answers back in seconds, using the same data that's in your Fospha dashboard. No login required.
MCP works with Claude and Cursor today, with ChatGPT and Perplexity coming next. You'll need an enterprise AI account (Claude for Work, ChatGPT Enterprise, or equivalent) to connect it.
Speak to your account manager to get set up.
Getting started with Fospha is quick and painless—most of our clients are up and running in less than 28 days with minimal effort.
All we need is admin access to your ad accounts, Google Analytics, and eCommerce platform—no coding or IT department needed!
Here's how it works:
- Initial Setup (about 3 hours): We'll help you connect your data through our easy-to-use onboarding portal.
- Data Validation (1-2 weeks): We'll verify your connections while you review initial insights for accuracy.
- Go-Live (by Day 28): You're all set! Full platform access with 24 months of historical data immediately available.
Your team includes an Onboarding Specialist for setup, a Customer Success Coordinator for ongoing support, and an Account Manager to help turn insights into growth opportunities
Fospha delivers the fastest time-to-value in marketing measurement, with most clients fully live in under 28 days.
Your onboarding timeline:
- Setup (3 hours): Connect your ad platforms, GA4, and eCommerce data via our easy-to-use Onboarding Portal.
- Data Validation (1-2 weeks): We reconcile and verify your data for accuracy, ensuring seamless measurement.
- Go-Live (by Day 28): Access 24 months of historical data from day one and start optimizing your performance immediately.
We take accuracy seriously. Our model undergoes daily quality checks to ensure reliable, fair measurement you can trust. Here's how we ensure accuracy:
- Data Validation First: Before anything enters our model, we verify your tracking is consistent across platforms, identify any gaps between channels, and run daily checks to confirm outputs align with expected patterns.
- Historical Back-Testing: We prove our value by showing how our model would have accurately predicted your past performance trends, giving you confidence our recommendations are reliable.
- Outlier Capping: During major sales events like Black Friday, ad platforms typically over-claim credit. Our system automatically adjusts the outputs on high-traffic days to maintain a fair picture of what's really driving results.
Yes, Fospha is built for privacy-first measurement, today and in the future.
For 10+ years, we've led the shift away from pixel-based tracking, building our solution to meet global privacy standards like GDPR, CCPA, and iOS14+, and preparing for changes like Google’s Privacy Sandbox.
Here’s how we do it:
No third-party cookies or user-level tracking: Our model doesn’t rely on personal identifiers or outdated tracking methods
- Privacy-first by design: Fospha combines always-on measurement signal with Daily MMM to restore visibility lost to privacy changes—without compromising compliance
- Proven compliance: Trusted by global brands across the US, UK, and EU, Fospha meets the highest privacy standards
Fospha uniquely combines the best of both worlds by unifying always-on measurement signal with Daily MMM - something our competitors simply don't offer.
While platform-native dashboards miss upper-funnel impact due to signal loss, and traditional MMM lacks the speed and granularity for daily decisions, we deliver:
- The granular, ad-level measurement insights for tactical optimization
- The predictive power and total channel visibility of our Daily MMM, fairly crediting both demand generation and capture channels
Our unified approach, refined through 10+ years of working with hundreds of brands, corrects the common measurement bias toward last-touch channels - properly valuing the complete channel mix from awareness to conversion.
Fospha measures your entire channel mix, from brand awareness to conversions, giving every channel fair credit using privacy-safe Daily MMM.
We cover everything that drives growth - across web, app, and Amazon - and unify it into a single, unbiased view.
What sets us apart:
- Halo Effect: Reveal how Meta, TikTok, and Google ads drive sales on Amazon - with unified ROAS across DTC and marketplace
- TikTok Shop: Track in-app and on-site purchases together, giving you full visibility into TikTok performance beyond what Google Analytics can capture
- App Sales: We model app and web sales separately to reflect how customers behave on each platform
With Fospha, you measure what matters - no blind spots, no wasted budget, just smarter growth.
Immediately.
Fospha gives you full-funnel, privacy-safe measurement from day one—so you can optimize spend, measure true channel impact, and make smarter decisions faster. Here's how different teams benefit from Fospha from day 1:
For Performance Marketers & Growth Teams:
- Stop wasted spend & scale smarter – Use Spend Strategist to forecast ROAS, conversions, and revenue at different spend levels—helping you scale efficiently.
- Optimize within & across channels – Get ad-level insights to improve performance and shift budgets strategically, even when direct reallocations aren’t possible.
For Marketing & Finance Leaders:
- Confident, bias-free reporting – Move beyond last-click limitations with independent, privacy-safe measurement trusted by CMOs and CFOs.
- Smarter budget decisions – Use Spend Strategist to forecast the most efficient spend levels before committing budget.
- See the full impact of marketing – Get daily, MMM-powered insights that quantify brand-building and performance marketing together.
No blind spots, no wasted budget - just better decisions from the very start.